Overview
You might’ve heard that TSA Security screeners failed 95% of tests conducted by Federal officials of Homeland Security. This revealed that several explosives and weapons are undetected through the body scanners. It was allegedly said that the reason is because of poor maintenance of the security screeners. But, the ground fact is that the algorithm itself is faulty which couldn’t classify better. There are many false negatives leading to long-lasting queues also.
As they have put their 3D-image screening dataset on Kaggle, I got an opputinity to explore the data for exploration. They splitted the problem into two stages, this project considers only stage-1 data. I arrived at converting 3D-image to 2D-image patches, took a particular patch, trained a model with all data corresponding to that patch. Then I wanted to scale it for whole 3D-image, but couldn’t finish due to lack of requirements (Data is in TBs and examining in AWS Cloud Platform consuming lot of runtime).
Dataset
Find the dataset at Kaggle PSA dataset. Data is pretty standard and all the cleaning is done by themselves before exposing it to Kaggle, hence I started making my EDA report(Exploratory Data Analysis).
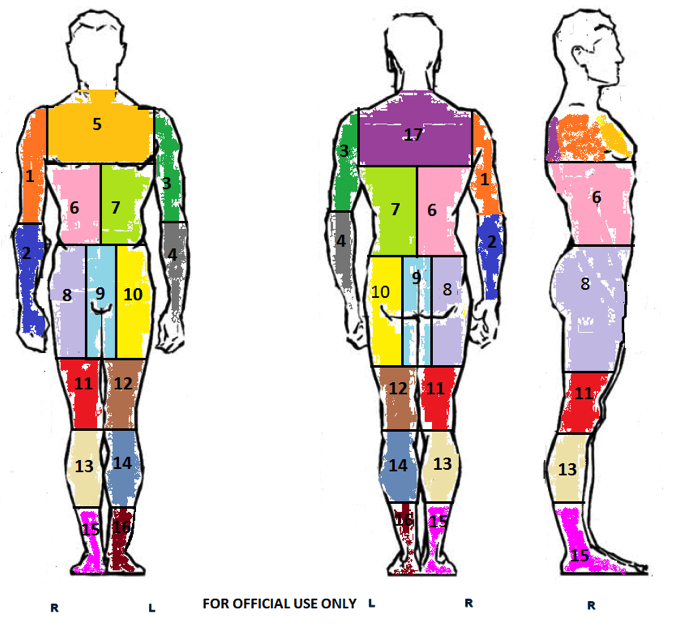
Zones about how many ways do they examine using the 3D-image from the body scanner is provided as shown below. Instrument used is also displayed. I’ve taken initially the reduced dataset of only zone 6, then working on scaling it to other zones.

Reading Datasets and working
Scanned 3D-images have a certain way to read in images for our analysis. A IPython Notebook regarding reading images in Python was posted in Kaggle Kernels by William Cukierski, which was very useful.
Kaggle has given another nice feature to this particular problem. It’s their integration with Google Cloud Storage Platform. They provided a bucket in the cloud system which is accessible during the competition period. See here for knowing about how to work with GCS buckets.
There are 4 formats of data for each entry. Description of them is in the Kaggle problem site. Please refer to it for better understanding of the terms.
.ahi(Raw image data, upto 2.26GB per file).ads(Projected image angle sequence, upto 10MB per file).a3d(Combined 3D image file, upto 330MB per file).a3daps(Combined image angle sequence, upto 41.2MB per file)
I’ve worked with .ads format, and even in that I’ve only taken Zone 6 initially. Then scaled Zone 6 that to .a3daps effectively.
Extracting Zone6 filenames
I’ve done this with the help of stage1_labels.csv given by Kaggle, which contains the probability value for each entry. I sampled the data which matches with Zone6 for 30 samples. The Jupyter Notebook I worked on, is here. I’ve included this in the project files too. If anyone wanted to sample their own set of images and work on them, they can change code here and start working.
My Deep learning model
I’ve created a simple Keras Artificial Neural Networks model in Python. The model is Squential and contains several Dense layers. Design summary for the optimizer which is used by KerasClassifier is:
- Sequential Classifier
- First Dense layer uses ReLU activation with uniform Kernel Initializer. Input Shape is
(512, 660, 16). - Followed by Dropout layer at rate
0.1. - Followed by Flatten over the dimensions.
- Now, another Dense layer(1) uses ReLU activation with uniform Kernel Initializer.
- Followed by Dropout layer(1) at rate
0.1. - Now, another Dense layer(2) uses ReLU activation with uniform Kernel Initializer.
- Followed by Dropout layer(2) at rate
0.1. - Now, another Dense layer(3) uses ReLU activation with uniform Kernel Initializer.
- Followed by Dropout layer(3) at rate
0.1. - Following these three duals of Dense and Dropout layers, a Dense layer uses Sigmoid activation with uniform Kernel Initializer.
- Then we compile the classifier with
optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy']parameters, which say that we use Binary Cross-Entropy loss function, with performance metrics to be evaluated on accuracy grounds.
Testing and Performance
I’ve used GridSearchCV in scikit-learn module for validation results. I’ve used Adam Optimizer and RMSProp Optimizer, number of epochs as 20 with batch size of 10. Based on that pipeline, it gave best parameters and best accuracy among several tests throughout the process. Observed that accuracy was 91% on Zone 6 and 45% on Zone 17. I’d love to extend it to full image whenever time and requirements permit.